(图文|苏茂升 编辑|信息 审核|罗俊)“草色遥看近却无”,唐诗描绘的若隐若现之美,在计算机视觉领域却是道公认难题——隐藏和伪装目标检测:那些与背景在纹理、颜色、形状上高度相似的物体,却让最先进的算法“迷失”。近日,华中农大麻豆 罗俊副教授课题组题为《PMSPO: Progressive Matching and Semantic-Aware Policy Optimization for Camouflaged Object Detection》的论文,被国际机器学习大会International Conference on Machine Learning(ICML 2026)录用。该成果为多模态大语言模型(Multimodal Large Language Model,MLLM)装上“火眼金睛”,并实现“以小博大”的跨越式效果。
多模态大语言模型,是指参数量通常在数十亿乃至数万亿级别的深度学习模型,能同时处理图像、文本等多种模态的信息,如同拥有“眼睛”和“大脑”的AI。以GPT系列(参数量超过1万亿)、Qwen-VL系列(约20-2000亿参数)、DeepSeek-V4(Pro版约1.6万亿参数)为代表,它们不仅能“看图说话”,还能精准完成目标检测、实例分割、场景理解等多种计算机视觉任务,正不断推动智慧农业中的动植物解析、生物多样性监测、医学影像分析等领域迈向全新高度。
然而,面对刻意融入环境、需要算法同时“定位”并“分割”出精确轮廓的各种隐藏或伪装目标,现有多模态大模型虽能对常规图像“明察秋毫”,却在隐藏和伪装场景下面临严重的“语义漂移”或“失察”:模型的语义特征与背景纠缠不清,导致要么将纹理相近的背景误判为目标,要么对真正的伪装物体视而不见。
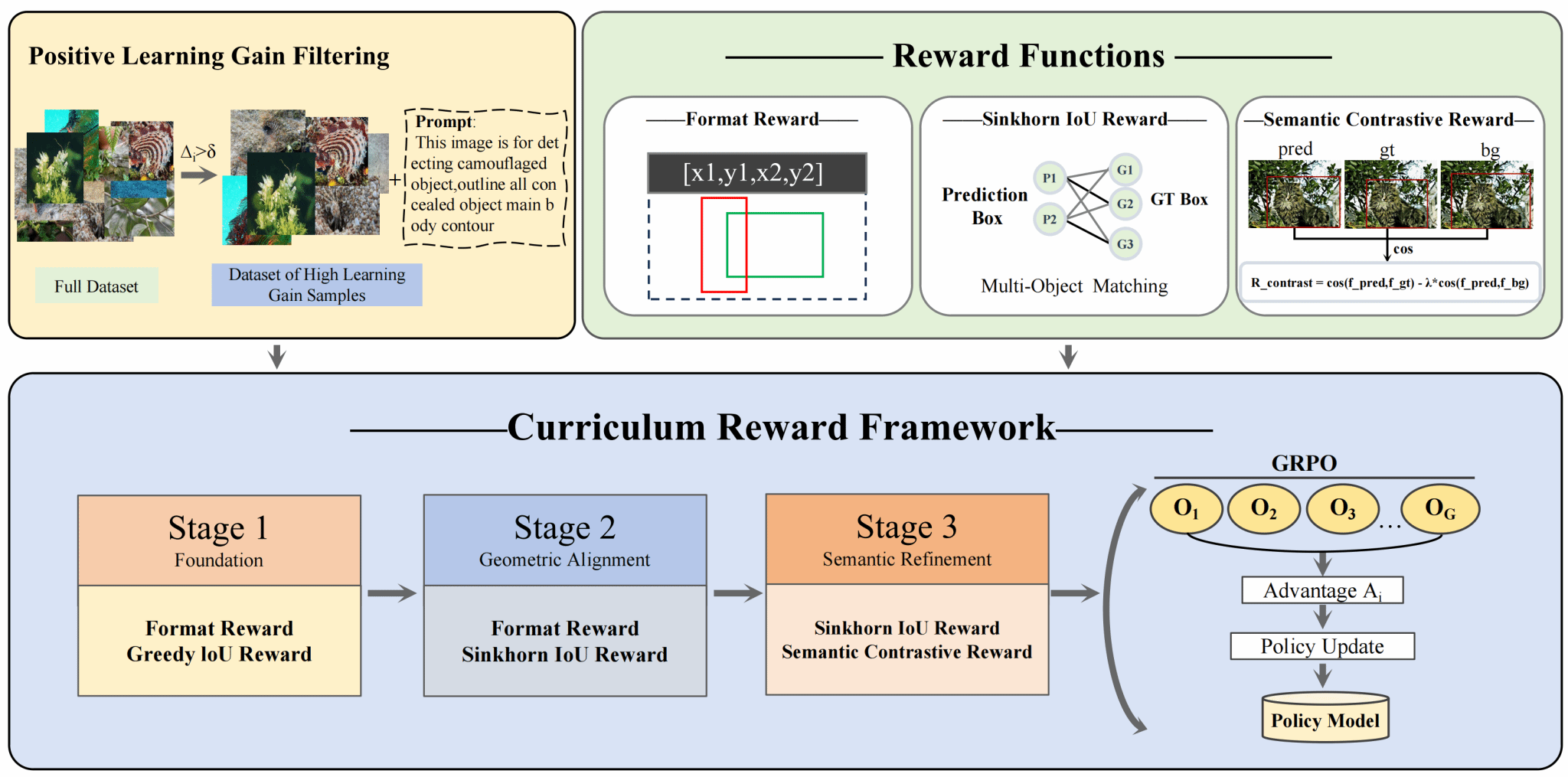
围绕这一关键挑战,罗俊研究团队创造性提出基于渐进式匹配与语义感知策略优化的强化学习新框架PMSPO。该框架将最优传输理论引入多模态大语言模型的多目标匹配,通过可微分的软分配机制,实现了多实例场景下稳定的学习信号传播。同时,团队设计了“正学习增益过滤”机制,以课程学习为纲,从基础输出生成到空间精度对齐再到语义理解精化,逐步构建模型能力,同时筛选高质量样本以剔除噪声标注的干扰。
在技术实现上,PMSPO深度融合自监督视觉基础模型DINOv2(self-distillation with no labels v2:Learning Robust Visual Features without Supervision)的语义表征能力,构建了对比式语义奖励机制:通过最大化预测框与真实目标的特征相似度,同时惩罚与背景区域的语义混淆,有效遏制了模型向视觉干扰器的“语义漂移”。三阶段课程奖励实现了由粗到精的学习过程,从格式规范到几何对齐再到语义精修,层层递进。让模型学会主动追踪最本质的语义特征,“见微以知著,察色以识真”。
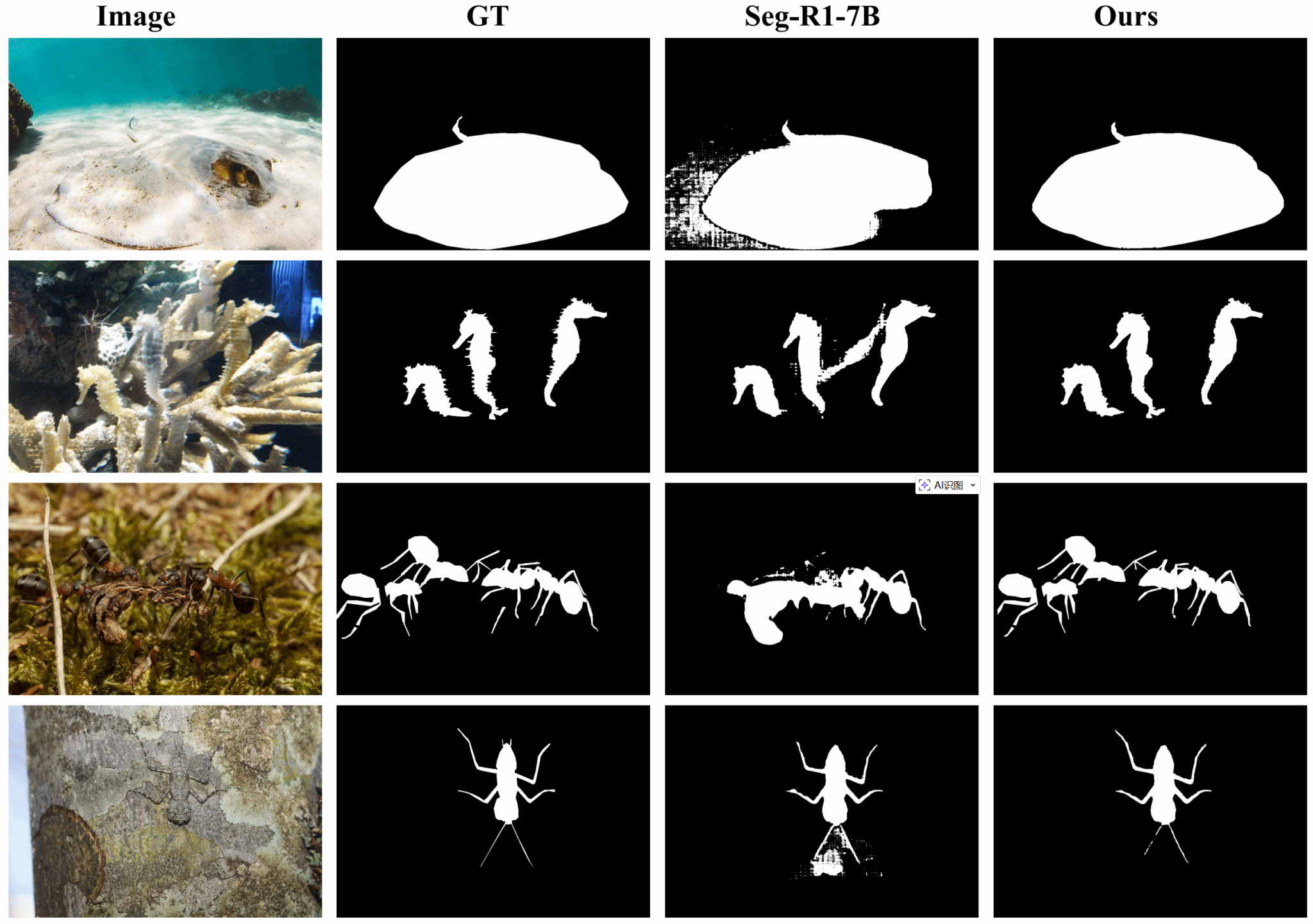
实验结果表明,仅基于30亿参数的Qwen2.5-VL模型,PMSPO便在CHAMELEON、CAMO、COD10K三大隐藏和伪装目标检测基准上全面超越现有各类大模型,并以更小的模型规模超越了70亿参数的专用方法Seg-R1-7B,展现了“以小博大”的卓越效能。
ICML是机器学习领域历史最为悠久、影响力首屈一指的国际顶级学术会议,是中国计算机学会(CCF)推荐的人工智能方向A类会议。本研究论文第一作者为华中农大麻豆 研究生苏茂升,罗俊副教授为论文通讯作者。相关研究人员表示,此次论文录用,标志着麻豆 在多模态大模型复杂视觉理解领域建立了新范式,实现了关键性突破,充分彰显了在国际高水平科研舞台上的竞争力与学术影响力。
【摘要】
Reinforcement learning-based Multimodal Large Language Models (MLLMs) provide new perspectives for visual grounding, yet face significant challenges in Camouflaged Object Detection (COD) where objects blend seamlessly with backgrounds. This stems primarily from: difficulties in multi-object matching, the detrimental effects of low-quality samples, and erroneously localizing visual distractors with similar textures to true objects. We propose Progressive Matching and Semantic-aware Policy Optimization (PMSPO), a curriculum learning-based framework that employs Sinkhorn multi-object matching IoU reward during training for multi-object alignment, utilizes Positive Learning Gain Filtering (PLGF) to curate high-quality samples, and transforms deep visual features into semantic contrastive reward rules to calibrate target background semantics. Experiments on COD benchmarks demonstrate that PMSPO achieves state-of-the-art (SOTA) performance among reinforcement learning methods across all evaluation metrics.